I always believed in "Trusting data" over human gut but lately I have
been observing a simple fact that being data driven has a side effect, "it motivates you and keeps you on track". Some recent examples are:
Fitbit: Last year I started the afternoon walk because by 2:00PM after doing calls and replying to a lot of emails the brain would be fried and I wont have energy left to code or think. Doing these 30 min walk daily recharges the brain. I had an Omron pedometer sitting around for almost an year and I seldom took it with me on walks. The problem with it was that it used to store last 30 days data of my steps and other things but it didn’t had a good way to graphically see the data. When it comes to data "less is more" but also one more important aspect is that you need to present your data in graphs so it doesn’t take a huge amount of cognitive effort to make sense of it. Recently my employer gave a fitbit to everyone who participated in summer challenge and it isn’t a better pedometer than my old Omron but immediately I saw that it can sync data stored on pedometer via bluetooth to my fitbit app and after a week I see this. Immediately in 1 sec I can see that I am lagging this week and need to catch up.
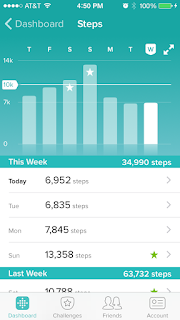
Its another thing that I need to remember to carry this dongle with me, I always carry my cell with me on walk and I saw that Iphone6 has a pedometer built into it so that would eliminate the need for this when I upgrade to Iphone6.

Large scale migration to Elasticsearch: We recently migrated billions of files to Elasticsearch and the migration took months but data kept us on toes and telling us if the compass is pointing towards north or not. We built various dashboard to monitor migration rates and as migration was running day and night I would start my day with checking how many more files we migrated and whether we need to add more servers, jvms, memory or CPU to meet the goal. Here is a graph in one data center.
 Data kept us on track and we were able to spot many issues before they were able to create a disaster.
Data kept us on track and we were able to spot many issues before they were able to create a disaster.
Exception Analysis: We do exceptions and 5xx status analysis on incoming requests daily and in 2 week sprint we strive to fix as many as we can, but after the release either new issues pops up or customers use the flow in a different way causing some components to buckle under pressure but one thing that has kept us on toes is data. By looking at the one screen report we can tell how did this data center do yesterday and which areas require immediate attention vs areas that require attention in 1-2 days. This leads to lesser no of customer escalations as we are able to spot many issues before them. Little little things adds up and having this report daily strives us to optimize more and we can spend quality time on doing things we love which is writing code for scalable systems.
In short data points you that there is a problem and once a bug has been implanted in your brain that a problem exists you would try to fix it so you can get back to normal routine.
Fitbit: Last year I started the afternoon walk because by 2:00PM after doing calls and replying to a lot of emails the brain would be fried and I wont have energy left to code or think. Doing these 30 min walk daily recharges the brain. I had an Omron pedometer sitting around for almost an year and I seldom took it with me on walks. The problem with it was that it used to store last 30 days data of my steps and other things but it didn’t had a good way to graphically see the data. When it comes to data "less is more" but also one more important aspect is that you need to present your data in graphs so it doesn’t take a huge amount of cognitive effort to make sense of it. Recently my employer gave a fitbit to everyone who participated in summer challenge and it isn’t a better pedometer than my old Omron but immediately I saw that it can sync data stored on pedometer via bluetooth to my fitbit app and after a week I see this. Immediately in 1 sec I can see that I am lagging this week and need to catch up.

Its another thing that I need to remember to carry this dongle with me, I always carry my cell with me on walk and I saw that Iphone6 has a pedometer built into it so that would eliminate the need for this when I upgrade to Iphone6.
Large scale migration to Elasticsearch: We recently migrated billions of files to Elasticsearch and the migration took months but data kept us on toes and telling us if the compass is pointing towards north or not. We built various dashboard to monitor migration rates and as migration was running day and night I would start my day with checking how many more files we migrated and whether we need to add more servers, jvms, memory or CPU to meet the goal. Here is a graph in one data center.
Exception Analysis: We do exceptions and 5xx status analysis on incoming requests daily and in 2 week sprint we strive to fix as many as we can, but after the release either new issues pops up or customers use the flow in a different way causing some components to buckle under pressure but one thing that has kept us on toes is data. By looking at the one screen report we can tell how did this data center do yesterday and which areas require immediate attention vs areas that require attention in 1-2 days. This leads to lesser no of customer escalations as we are able to spot many issues before them. Little little things adds up and having this report daily strives us to optimize more and we can spend quality time on doing things we love which is writing code for scalable systems.
In short data points you that there is a problem and once a bug has been implanted in your brain that a problem exists you would try to fix it so you can get back to normal routine.
Comments
Post a Comment